結論
(long)x << 32 | y をDictionaryのキーにすると性能が悪化して死ぬ(のでTuple<int, int>を使おう)
前提知識
C#では、ハッシュテーブル(Dictionary型)に値を格納する場合に、ハッシュ値として、object.GetHashCode() の値を使用します。このGetHashCode()の実装によっては、効率的にハッシュテーブルを使用することができません。ということで、long型のGetHashCode()の実装がどのようになっているか見てみたいと思います。
話の発端
競技プログラミングなどでは、2個のintをペアにしてHashSetやDictionaryに格納したいことがよくあると思います。が、
(x,y)を((long)x<<32)+yでエンコードするとハッシュ衝突して死ぬ、普通に知らなかった。(C#のDictionaryの内部実装の問題っぽい)
— chokudai(高橋 直大) (@chokudai) 2017年4月16日
Dictionaryの内部実装というよりはlongのGetHashCodeの内部実装の話だったっぽい
— chokudai(高橋 直大) (@chokudai) 2017年4月16日
ということなので、Monoのlong.GetHashCode()の実装を見てみますと、
mono int64 gethashcode github [Google検索] ポチー
// The value of the lower 32 bits XORed with the uppper 32 bits.
public override int GetHashCode() {
return (unchecked((int)((long)m_value)) ^ (int)(m_value >> 32));
}
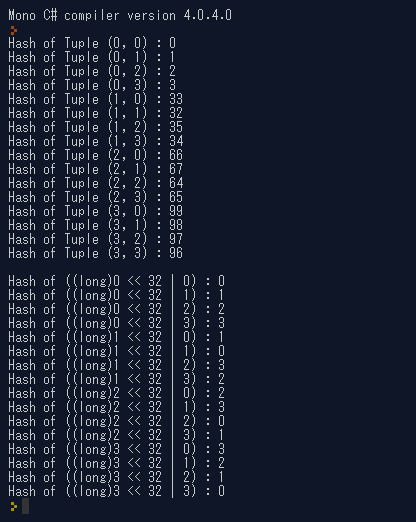
ハッシュテーブルのハッシュ値というのはバラければバラけるほど良いのですが、この場合では上位32ビットと下位32ビットのXORを取っていて、死んでいることがわかります。
Hash of ((long)0 << 32 | 0) : 0 Hash of ((long)0 << 32 | 1) : 1 Hash of ((long)0 << 32 | 2) : 2 Hash of ((long)0 << 32 | 3) : 3 Hash of ((long)1 << 32 | 0) : 1 Hash of ((long)1 << 32 | 1) : 0 Hash of ((long)1 << 32 | 2) : 3 Hash of ((long)1 << 32 | 3) : 2 Hash of ((long)2 << 32 | 0) : 2 Hash of ((long)2 << 32 | 1) : 3 Hash of ((long)2 << 32 | 2) : 0 Hash of ((long)2 << 32 | 3) : 1 Hash of ((long)3 << 32 | 0) : 3 Hash of ((long)3 << 32 | 1) : 2 Hash of ((long)3 << 32 | 2) : 1 Hash of ((long)3 << 32 | 3) : 0
Tuple<int, int>はどうなの?
ここで、こんな疑問が生じます。
Tuple<int,int>とかはどうなんだろ
— めりあしぐ (@meliasig) 2017年4月16日
ではMonoのソースコードを調べてみます。
public override int GetHashCode() {
return ((IStructuralEquatable) this).GetHashCode(EqualityComparer<Object>.Default);
}
ふむ
Int32 IStructuralEquatable.GetHashCode(IEqualityComparer comparer) {
return Tuple.CombineHashCodes(comparer.GetHashCode(m_Item1), comparer.GetHashCode(m_Item2));
}
ふむふむ
// From System.Web.Util.HashCodeCombiner
internal static int CombineHashCodes(int h1, int h2) {
return (((h1 << 5) + h1) ^ h2);
}
なるほど。
5ビット左シフトして元の数を加えて(=33倍して)、他方のハッシュ値をXORしている・・・ pic.twitter.com/lQaW8twBI1
— めりあしぐ (@meliasig) 2017年4月16日
ということで、((x << 5) + x) ^ y がハッシュになるようです。幸せ。ということで、極限まで速くしたいのでなければTupleを使うのが良いと思います。
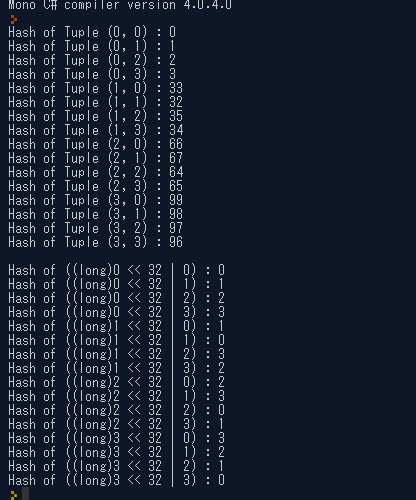
Hash of (0, 0) : 0 Hash of (0, 1) : 1 Hash of (0, 2) : 2 Hash of (0, 3) : 3 Hash of (1, 0) : 33 Hash of (1, 1) : 32 Hash of (1, 2) : 35 Hash of (1, 3) : 34 Hash of (2, 0) : 66 Hash of (2, 1) : 67 Hash of (2, 2) : 64 Hash of (2, 3) : 65 Hash of (3, 0) : 99 Hash of (3, 1) : 98 Hash of (3, 2) : 97 Hash of (3, 3) : 96
検証に使用したコード
using System;
public class Test
{
public static void Main()
{
// your code goes here
for (int i = 0; i < 4; i++)
{
for (int j = 0; j < 4; j++)
{
Console.WriteLine(
"Hash of Tuple (" + i + ", " + j + ") : " +
Tuple.Create(i, j).GetHashCode());
}
}
Console.WriteLine();
for (int i = 0; i < 4; i++)
{
for (int j = 0; j < 4; j++)
{
Console.WriteLine(
"Hash of ((long)" + i + " << 32 | " + j + ") : " +
((long)i << 32 | j).GetHashCode());
}
}
}
}
蛇足
((long)i << 32 | j) にすると j が符号拡張されてしまうので、 ((long)i << 32 | (uint)j) にすべきだったのでは、と後からVisual Studioの警告を見て気付きました。(i, j >= 0 なら問題なし)

{kind=link}
{kind=link}