SIMD 単精度命令のスループットとレイテンシ(抜粋)
以下の値は 2022 年版の intel 最適化マニュアル(インテル® 64 および IA-32 アーキテクチャー 最適化リファレンス・マニュアル参考訳)から引用しています。これより新しいものは見つけられませんでした。
| 命令 | C++/Rust 関数名 | レイテンシー (06_4E, 06_5E) |
スループット (06_4E, 06_5E) |
備考 |
|---|---|---|---|---|
| ALL VFMA | _mm256_fmadd_ps | 4 | 0.5 | |
| VADDPS | _mm256_add_ps | 4 | 0.5 | |
| VSUBPS | _mm256_sub_ps | 4 | 0.5 | |
| VADDSUBPS | _mm256_addsub_ps | 4 | 0.5 | |
| VMULPS | _mm256_mul_ps | 4 | 0.5 | |
| VDIVPS | _mm256_div_ps | 11 | 5 | fp32 |
| HADDPS | _mm256_hadd_ps | 6 | 2 | |
| HSUBPS | _mm256_hsub_ps | 6 | 2 | |
| VANDPS | _mm256_and_ps | 1 | 0.33 | |
| VORPS | _mm256_or_ps | 1 | 0.33 | |
| VXORPS | _mm256_xor_ps | 1 | 0.33 | |
| VBLENDPS | _mm256_blend_ps | 1 | 0.33 | |
| VSHUFPS | _mm256_shuffle_ps | 1 | 1 | |
| VUNPCKHPS | _mm256_unpackhi_ps | 1 | 1 | |
| VUNPCKLPS | _mm256_unpacklo_ps | 1 | 1 | |
| VMOVSHDUP | _mm256_movehdup_ps | 1 | 1 | |
| VMOVSLDUP | _mm256_moveldup_ps | 1 | 1 | |
| VMOVAPS | – | 1 | 0.25 | |
| VPERMILPS | _mm256_permute_ps | 1 | 1 | |
| VPERM2F128 | _mm256_permute2f128_ps | 3 | 1 | |
| (参考) IDIV r32 | – | – | ~26 | 非 SIMD、整数 |
| (参考) IDIV r64 | – | – | ~100 | 非 SIMD、整数 |
大きな効果的があった改善
- float 1 個に対する平均演算回数が多い箇所の SIMD 化
- 数学関数 (sin, cos) のメモ化(ルックアップテーブルの作成)
- 引数(角度)が有限個ではなく、高い精度が欲しい場合は、 n 次導関数もメモ化し、テイラー展開による近似を使用しても良いかもしれない
- または線形補間でも可
- 他にも良いアイディアがもしあれば
- 非定数の 2 の累乗数による除算をビットシフト演算にする
- 非定数の 2 の累乗数による剰余をビットアンド演算にする
今回は SIMD を導入することでおよそ 3 倍程度の高速化ができました。
効果的ではなかった改善
- 整数同士の、定数による乗算をビット演算にする
- 自動で最適化されているか、最適化しなくても十分早いかのどちらか
- 整数同士の、定数による除算・整数剰余をビット演算にする
- 自動で最適化されている
雑感1:メモリが遅い
メモリアクセスがとても遅いので、データ 1 個に対する平均演算回数が少ない場合は SIMD 演算を使用しても効果的に高速化されない場合がある。
また、処理を行うブロックが大きすぎる場合も、メモリアクセスがボトルネックになる場合がある。L1/L2 キャッシュに収まる範囲ごとに処理をすると速度が上がることがある。
雑感2:シャッフル命令はレイテンシが少ない
VBLENDPS や VSHUFPS などのシャッフル系命令はレイテンシーが少ないため、頻繁に使用してもそれほど問題なさそうだった。これらを使うことでレジスタ間の依存関係を減らせるのであれば(クリティカルパスを短くできるのであれば)それでも良いかもしれない。
ただし、128 ビット境界を超える場合 (VPERM2F128) はレイテンシが増加してしまうため、可能ならなるべく超えないようにデータを配置した方が良い。
雑感3:HADDPS / HSUBPS は若干遅い
無理に HADDPS / HSUBPS は使わなくても良いかもしれない。特にこれを使ったからと言って命令あたりの加算・減算回数が増えるわけではない。
雑感4:FMA (Fused Multiply-Add) は使った方が良い
レイテンシ及びスループットが VADDPS / VSUBPS と同じなので、使い得っぽい。
雑感5:ビット演算は速い
それはそう。ただし浮動小数点の場合は符号反転と絶対値、ゼロクリアくらいでしか使わないかも。
小ネタ5 実数の絶対値 – x86/x64 SIMD命令一覧表 (SSE~AVX2)
雑感6:ループアンローリングはしんどい
楽しい範囲で SIMD プログラミングで遊ぶのは良いが、過剰なループアンローリングを始めると楽しさよりもしんどさが勝ってしまうので、ほどほどの箇所で切り上げるのも勇気。
その他、面白い知見 1
Rust において、同一関数内で定義されたローカル変数が 2 の累乗数であると明確に分かる場合、最適化により除算・剰余命令をビットシフト演算に置き換えることがある。
例:
let mut step = 1;
while step < n {
let idx = n / step;
step *= 2;
}
ただし、関数に切り出して、そのローカル変数を引数として与えてしまうと、その最適化は行われない場合がある。
その他、面白い知見 2
Rust で非定数での整数除算を行う場合、32 ビット整数の範囲に収まるかどうかを調べ、もし収まるなら 32 ビット整数用の DIVL 命令を、収まらないなら 64 ビット整数用の DIVQ 命令を使うということが分かった。すごいなと思った。(すごいのが LLVM なのか Rust なのか、までは分かっていない。)
例:
return x % y;
asm:
movq %rdx, %r8
movq %rcx, %rax
orq %rdx, %rax
shrq $32, %rax
je .LBB8_2 ; if ((x | y) >> 32) != 0
movq %rcx, %rax
xorl %edx, %edx
divq %r8 ; x / y
movq %rdx, %rax
.seh_startepilogue
addq $40, %rsp
.seh_endepilogue
retq
.LBB8_2: ; else
movl %ecx, %eax
xorl %edx, %edx
divl %r8d ; (i32)x / (i32)y
movl %edx, %eax
.seh_startepilogue
addq $40, %rsp
.seh_endepilogue
retq
その他、面白い知見 3
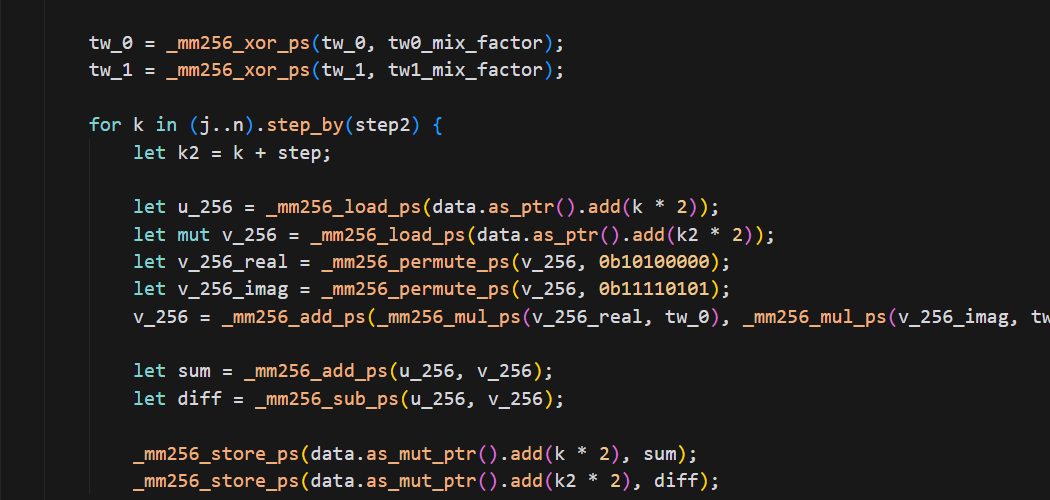
第二引数が特殊な定数の場合の __mm256_permute_ps の呼び出しは、より最適な別の命令 (VMOVSLDUP など) に最適化されることがあるらしい。
![[C#] Regex.Replace() じゃなくて string.Replace() が使いたい](https://yuinore.net/wp-content/themes/customizr/assets/front/img/thumb-standard-empty.png)